iPhoneでのピクセル処理をNEON(ベクタ演算)を使って4倍高速化する
目次
- はじめに
- どのような処理をするのか?
- コードの入手先
- C言語でのコード
- アセンブラでのコードとgccの最適化の素晴らしさ
- NEON : 資料
- NEON : 処理の流れと制限
- NEON : コード
- NEON : コード解説-処理限界数でのループ
- NEON : コード解説-レジスタの役割
- NEON : コード解説-データの読込
- NEON : コード解説-加算
- NEON : コード解説-ピクセルの色チェックとカウント
- NEON : コード解説-カウントの合計
- 終りに
はじめに
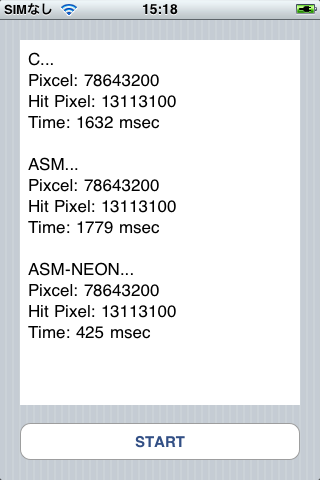 ARMのNEONというベクタ演算を使ってコードを書いたところ、C言語で書いたコードの4倍の速度で動作する事ができました。この記事では、C言語でのコードの紹介、アセンブラでのコードの紹介、そしてNEONを利用したコードの紹介を行い、高速化を実現させた手法を書きます。
ARMのNEONというベクタ演算を使ってコードを書いたところ、C言語で書いたコードの4倍の速度で動作する事ができました。この記事では、C言語でのコードの紹介、アセンブラでのコードの紹介、そしてNEONを利用したコードの紹介を行い、高速化を実現させた手法を書きます。
どのような処理をするのか?
![]()
弊社からリリースしている自炊系読書アプリ「吾輩の小説 for iPhone」は、画像のピクセルを全てチェックして文章を整形して表示しています。この処理がとても重いので最適化の一貫として研究した情報を公開します。
このプログラムでは 1024x768 ピクセルでRGBAのフォーマットをもつデータから、RGBの各色の合計値が256未満であるピクセルの数を計算します。つまり、画像データから黒っぽいピクセルがいくつあるのかを計算します。また、計算速度の違いが分かりやすくなるように、これを100回繰り返し合計で約8000万ピクセルの計算を行ないます。また、その計算時間を表示します。
コードの入手先
githubにプロジェクトファイルも含めてiPhoneで実行できるファイル一式をアップしましたのでご利用ください。gitコマンドを使用しない場合はこちらからzip化したものを落としてください。
C言語でのコード
以下がコードになります。
#define IMAGE_SIZE_W (1024)
#define IMAGE_SIZE_H (768)
#define CHECK_COLOR (0xFF)
#define LOOP_COUNT (100)
#define ELEMENT_OF_PIXEL (4)
NSString* Test::testC(){
int pixelCount = width * height;
int hitCount = 0;
int startTime = getTime();
for(int i = 0; i < LOOP_COUNT; i++){
unsigned char* imageWork = image;
for(int j = 0; j < pixelCount; j++){
int color = imageWork[0]+imageWork[1]+imageWork[2];
if(color < CHECK_COLOR){
hitCount++;
}
imageWork += ELEMENT_OF_PIXEL;
}
}
int endTime = getTime();
NSString* string = [NSString stringWithFormat:@"Pixel: %d\nHit Pixel: %d\nTime: %d msec\n", pixelCount * LOOP_COUNT, hitCount, endTime-startTime];
return string;
}
RGBの合計値を算出し、CHECK_COLOR(0xFF) よりも小さいものをカウントしていくだけのシンプルなプログラムです。
アセンブラでのコードとgccの最適化の素晴らしさ
以下がコードになります。
#define IMAGE_SIZE_W (1024)
#define IMAGE_SIZE_H (768)
#define CHECK_COLOR (0xFF)
#define LOOP_COUNT (100)
#define ELEMENT_OF_PIXEL (4)
NSString* Test::testAsm(){
int pixelCount = width * height;
int hitCount = 0;
int checkColor = CHECK_COLOR;
int startTime = getTime();
for(int i = 0; i < LOOP_COUNT; i++){
__asm__ volatile (
"mov r0, #0 \n\t"
// ループ開始
"1: \n\t"
"add r0, r0, #1 \n\t"
"ldrb r3, [%[image]] \n\t"
"ldrb r2, [%[image], #1] \n\t"
"add r2, r2, r3 \n\t"
"ldrb r3, [%[image], #2] \n\t"
"add r2, r2, r3 \n\t"
"add %[image], %[image], #4 \n\t"
// 色判定とカウント
"cmp r2, %[checkColor] \n\t"
"addlt %[hitCount], %[hitCount], #1 \n\t"
// 「ループ開始」へ戻る
"cmp r0, %[pixelCount] \n\t"
"bne 1b \n\t"
: [hitCount] "+r" (hitCount)
: [pixelCount] "r" (pixelCount), [image] "r" (image), [checkColor] "r" (checkColor)
: "r0", "r1", "r2", "r3", "cc", "memory"
);
}
int endTime = getTime();
NSString* string = [NSString stringWithFormat:@"Pixcel: %d\nHit Pixel: %d\nTime: %d msec\n", pixelCount * LOOP_COUNT, hitCount, endTime-startTime];
return string;
}
時間を計測したところ、驚くことに C言語 で書いたものよりも速度が遅くなりました。gccがCからアセンブラにコンパイルする時の最適化がとても優れているのだと思います。NEONなどの特殊な機能を使わないかぎりは、アセンブラ化せず C言語 で書くほうが良いと思います。
NEON : 資料
今回のコードでお見苦しい点があればご容赦願います。アセンブラでの開発経験が全く無く2日前に勉強しながら作成したものです。そこで、使用した資料を列挙しておきます。
- ARM アセンブリ
ARMの基本的なプログラミングの手法を知る事ができます。 - iPhoneでインラインアセンブラを使う
iPhoneでアセンブラを使用する時の手法を知る事ができます。 - ARM Cortex-A8 の NEON と浮動小数演算最適化
NetWalker PC-Z1 Cortex-A8 (ARM) 浮動小数演算の実行速度
NEONのレジスタや計算の雰囲気を知ることができます。 - RealView® Compilation Tools アセンブラガイド バージョン 4.0
ARM命令が網羅されているリファレンスです。ただし、バージョンが古いせいか今回使用している一部の命令は載っていません。 - Coding for NEON - Part 1: Load and Stores
メモリからNEONレジスタにデータを読み込む時の参考になる資料です。
NEON : 処理の流れと制限
NEONはベクタ演算です。ベクタ演算とは復数の演算を1命令で実行します。今回の方法では、16回の足し算、16回の比較などを1命令で実行します。それにともなって、今までの単純なループや比較ではなくて、それなりに複雑なプログラムになってきます。処理の大まかな流れは以下の順番になります。
16ピクセル(64バイト)分のデータを詠込む
16ピクセルのRGBを一気に足す
16ピクセルの0xFF未満の値を一気にカウンタに追加
4096ピクセルの処理が終わるまで1-3を繰返す
カウンタの合計を取る
全てのピクセルの処理が終わるまで1-5を繰返す
ポイントは「16ピクセルを一気に処理」している所と、「4096ピクセルの処理」を一つの境目としている所です。以下で詳しく説明していきます。
NEON : コード
以下がコードになります。
#define IMAGE_SIZE_W (1024)
#define IMAGE_SIZE_H (768)
#define CHECK_COLOR (0xFF)
#define LOOP_COUNT (100)
#define ELEMENT_OF_PIXEL (4)
NSString* Test::testNeon(){
int pixelCount = 4096;
int innerLoop = ((width*height)/pixelCount);
int totalHitCount = 0;
unsigned int checkColor =
CHECK_COLOR << 24 |
CHECK_COLOR << 16 |
CHECK_COLOR << 8 |
CHECK_COLOR << 0;
int startTime = getTime();
unsigned int addMask = 0x01010101;
for(int i = 0; i < LOOP_COUNT; i++){
unsigned char* _image = image;
for(int j = 0; j < innerLoop; j++){
int hitCount = 0;
__asm__ volatile (
// 初期化
"mov r0, #0 \n\t" // 0クリア用
"mov r1, #0 \n\t" // 処理済みピクセルのカウンタ
"vmov.u32 d8, r0, r0 \n\t"
"vmov.u32 d9, r0, r0 \n\t"
"vmov.u32 d10, %[checkColor], %[checkColor] \n\t"
"vmov.u32 d11, %[checkColor], %[checkColor] \n\t"
"vmov.u32 d12, %[addMask], %[addMask] \n\t"
"vmov.u32 d13, %[addMask], %[addMask] \n\t"
// ループ開始
"1: \n\t"
"add r1, r1, #16 \n\t"
// データの読込と色の加算
"add r2, %[image], #32 \n\t"
"vld4.8 {d0, d2, d4, d6}, [%[image]] \n\t"
"vld4.8 {d1, d3, d5, d7}, [r2] \n\t"
"vqadd.u8 q0, q1 \n\t"
"vqadd.u8 q0, q2 \n\t"
// 色の判定とカウント
"vclt.u8 q1, q0, q5 \n\t"
"vand q1, q6 \n\t"
"vadd.u8 q4, q4, q1 \n\t"
// データのアドレスを進める
"add %[image], #64 \n\t"
// 「ループ開始」へ
"cmp r1, %[pixelCount] \n\t"
"bcc 1b \n\t"
// 色数の合計
"mov r0, #0 \n\t"
"vmov.u32 r1, d8[0] \n\t"
"2: \n\t"
"and r2, r1, #0xFF \n\t"
"add %[hitCount], r2 \n\t"
"lsr r1, #8 \n\t"
"add r0, #1 \n\t"
"cmp r0, #4 \n\t"
"bne 2b \n\t"
"mov r0, #0 \n\t"
"vmov.u32 r1, d8[1] \n\t"
"3: \n\t"
"and r2, r1, #0xFF \n\t"
"add %[hitCount], r2 \n\t"
"lsr r1, #8 \n\t"
"add r0, #1 \n\t"
"cmp r0, #4 \n\t"
"bne 3b \n\t"
"mov r0, #0 \n\t"
"vmov.u32 r1, d9[0] \n\t"
"4: \n\t"
"and r2, r1, #0xFF \n\t"
"add %[hitCount], r2 \n\t"
"lsr r1, #8 \n\t"
"add r0, #1 \n\t"
"cmp r0, #4 \n\t"
"bne 4b \n\t"
"mov r0, #0 \n\t"
"vmov.u32 r1, d9[1] \n\t"
"5: \n\t"
"and r2, r1, #0xFF \n\t"
"add %[hitCount], r2 \n\t"
"lsr r1, #8 \n\t"
"add r0, #1 \n\t"
"cmp r0, #4 \n\t"
"bne 5b \n\t"
: [hitCount] "+r" (hitCount)
: [pixelCount] "r" (pixelCount), [image] "r" (_image), [checkColor] "r" (checkColor), [addMask] "r" (addMask)
: "r0", "r1", "r2", "q0", "q1", "q2", "q3", "q4", "cc", "memory"
);
totalHitCount += hitCount;
}
}
int endTime = getTime();
NSString* string = [NSString stringWithFormat:@"Pixcel: %d\nHit Pixel: %d\nTime: %d msec\n", width * height * LOOP_COUNT, totalHitCount, endTime-startTime];
return string;
}
NEON : コード解説-処理限界数でのループ
上記しましたが、この処理でのポイントに「4096ピクセルの処理」というものがあります。これはピクセル数のカウントを1バイトで行い、それを16個保持しているからです。「256(1バイト)x16=4096」となります。なぜ1バイトで計算するのか?と思われるとおもいますが、これがベクタ演算を使った高速化のカギになります。以下で説明します。
NEON : コード解説-レジスタの役割
この最適化コードでは7本のNEON128ビットレジスタを使用しています。それぞれの主な役割は以下のようになります。
q0(d0,d1): R値を保持
q1(d2,d3): G値を保持
q2(d4,d5): B値を保持
q3(d6,d7): A値を保持。読込むだけで計算には使わない。
q4(d8,d9): 色判定の結果をカウント
q5(d10,d11): 色判定で使用する値(0xFFが詰まっている)
q6(d12,d13): 結果をカウントするときに使用するビットマスク(0x01が詰まっている)
NEON : コード解説-データの読込
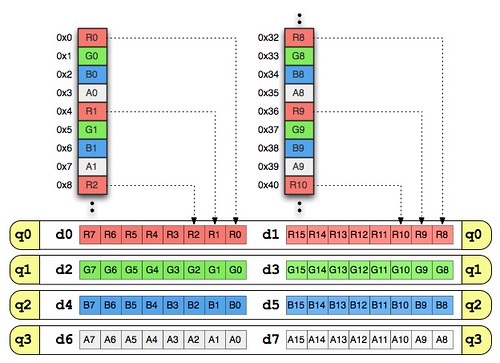
まず、計算の前にメモリからNEONレジスタにデータを読み込みます。
// データの読込と色の加算
"add r2, %[image], #32 \n\t"
"vld4.8 {d0, d2, d4, d6}, [%[image]] \n\t"
"vld4.8 {d1, d3, d5, d7}, [r2] \n\t"
%[image]レジスタがデータの先頭のアドレスを指し、r2レジスタがそこから32バイトずらした8個目以降のピクセルのアドレスを指しています。そして vld4.8 命令を呼び以下の画像のような配置でデータが読み込まれます。
NEON : コード解説-加算
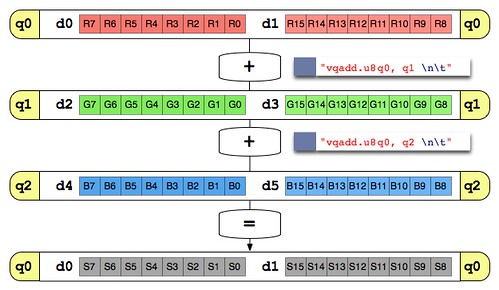
そして、RGBの値を加算します。
"vqadd.u8 q0, q1 \n\t"
"vqadd.u8 q0, q2 \n\t"
Rの値が入っている q0 レジスタに、G値の q1 と、B値の q2 を加算します。以下の図ような処理になります。
この時に vadd.u8 ではなく vqadd.u8 を使います。前者は加算時にビットが溢れても気にせずに計算がされます。後者はビットが溢れた場合に最大値が設定されます。計算式でたとえると以下のような違いになります。
vadd.u8 : 0xFF + 0x01 = 0x0
vqadd.u8 : 0xFF + 0x01 = 0xFF
これで次に行う比較演算が問題なくおこなえます。
しかし、正確にいうと場合によっては問題が大ありです。上記のとおり、この最適化コードでは256以上の値での色判定は行えません。どんな値でも判定できるコードも書いてみたのですが、これがあまり高速化できなかったため今回はバッサリと切り捨てました。
NEON : コード解説-ピクセルの色チェックとカウント
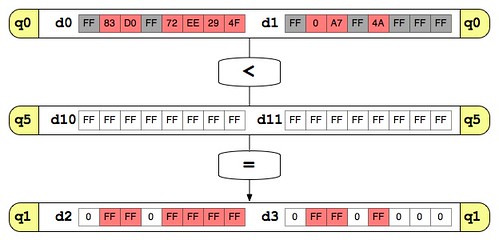
ピクセルの色チェックとカウントは多少やっかいなので、図をまじえつつ説明していきます。
// 色の判定とカウント
"vclt.u8 q1, q0, q5 \n\t"
"vand q1, q6 \n\t"
"vadd.u8 q4, q4, q1 \n\t"
vclt.u8 は比較命令です。 RGBの合計値が入っている q0 と、比較用の値を詰め込んである q5 を比較し、 q0 の値の方が小さかった場合に対応するビットに 1 が設定された値を q1 に入れます。意味が分かりにくいと思うので図では以下のようになります。例として q0 にはRGB値が加算されたとして適当な値を入れています。
次は、比較判定にヒットしたピクセルをカウントします。vclt.u8 では比較にヒットしたピクセルに対応する箇所のビットが全て立つ、つまり 0xFF が入っています。これを 1 になるように 0x1 で AND を取ります。
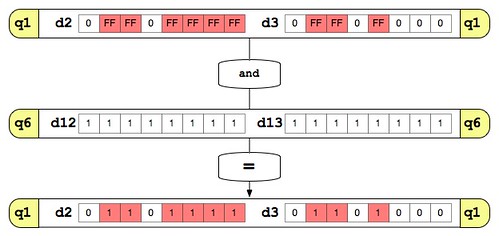
最後に vadd.u8 で q4 に q1 を足してあげれば、16ピクセル分のカウントが完了します。
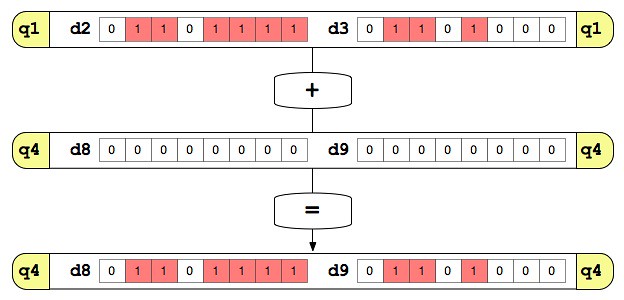
上記の図ではカウント用の q4 レジスタが空でしたが、ループを重ねるごとに値が加算されていくことになります。
NEON : コード解説-カウントの合計
上記したように、このコードでは4096ピクセルまで計算すると、q4 でのカウンタが最大値である 0xFF になるものが出てきます。ですので、ここで一度別のレジスタに待避させます。
// 色数の合計
"mov r0, #0 \n\t"
"vmov.u32 r1, d8[0] \n\t"
"2: \n\t"
"and r2, r1, #0xFF \n\t"
"add %[hitCount], r2 \n\t"
"lsr r1, #8 \n\t"
"add r0, #1 \n\t"
"cmp r0, #4 \n\t"
"bne 2b \n\t"
//以下の同様の処理は省略
まず vmov.u32 で d80 を r1 レジスタにコピーします。and で 下位1バイトに格納されているカウンタを取り出し %[hitCount] に足します。lsr r1, #8 で1バイト分右にシフトし次のカウンタの値を取得する準備をします。and と lsr の処理は以下の図のようになります。
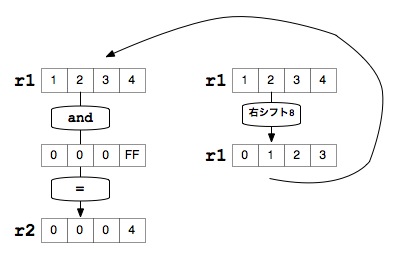
これらの処理をループで4回まわして、合計4個のカウント値を合計します。
その後 d8[1] d9[0] d9[1] にも同様の処理を行ない、16個を合計します。
これまでの処理を画像データの最後まで繰り返すと、RGB合計値が256未満の色をもつピクセル(黒っぽいピクセル)の個数が、C言語で書いたプログラムの約4倍の速度で取得できます。
終りに
今回最適化を行うにあたって上記のコード量の10倍程度を書き検証しました。そこで分かった注意点が、NEONで最適化するなら、メモリロードなどにARMレジスタや命令を使わずに、直接NEONレジスタと命令を使わないと意味が無いという事です。
決して汎用的な最適化コードではないですが、iPhoneで大量の処理を行う必要がある場合に、NEONでの高速化は有効だと思います。その時の参考になれば幸いです。
最後に、NEONを使いながらC言語の処理速度とほぼ同じだったコードを書いておきます。
#define IMAGE_SIZE_W (1024)
#define IMAGE_SIZE_H (768)
#define CHECK_COLOR (0xFF)
#define LOOP_COUNT (100)
#define ELEMENT_OF_PIXEL (4)
NSString* Test::testNeon(){
int pixelCount = width * height;
int totalHitCount = 0;
int checkColor = CHECK_COLOR;
int startTime = getTime();
unsigned int a = 0;
for(int i = 0; i < LOOP_COUNT; i++){
int hitCount = 0;
__asm__ volatile (
// 初期化
"mov r0, #0 \n\t"
"vmov.u32 d8, r0, r0 \n\t"
"vmov.u32 d9, r0, r0 \n\t"
"vmov.u32 d6, %[checkColor], %[checkColor] \n\t"
"vmov.u32 d7, %[checkColor], %[checkColor] \n\t"
// ループ開始
"1: \n\t"
"add r0, r0, #4 \n\t"
"ldrb r1, [%[image]] \n\t"
"ldrb r2, [%[image], #1] \n\t"
"ldrb r3, [%[image], #2] \n\t"
"ldrb r4, [%[image], #4] \n\t"
"ldrb r5, [%[image], #5] \n\t"
"ldrb r6, [%[image], #6] \n\t"
"vmov d0, r1, r4 \n\t"
"vmov d2, r2, r5 \n\t"
"vmov d4, r3, r6 \n\t"
"ldrb r1, [%[image], #8] \n\t"
"ldrb r2, [%[image], #9] \n\t"
"ldrb r3, [%[image], #10] \n\t"
"ldrb r4, [%[image], #12] \n\t"
"ldrb r5, [%[image], #13] \n\t"
"ldrb r6, [%[image], #14] \n\t"
"vmov d1, r1, r4 \n\t"
"vmov d3, r2, r5 \n\t"
"vmov d5, r3, r6 \n\t"
"add %[image], %[image], #16 \n\t"
"vadd.s32 q0, q0, q1 \n\t"
"vadd.s32 q0, q0, q2 \n\t"
// カウント
"vclt.s32 q1, q0, q3 \n\t"
"vsub.s32 q4, q4, q1 \n\t"
// 「ループ開始」へ
"cmp r0, %[pixelCount] \n\t"
"bcc 1b \n\t"
// 色判定とカウント
"vmov.s32 %[hitCount], d8[0] \n\t"
"vmov.s32 r0, d8[1] \n\t"
"vmov.s32 r1, d9[0] \n\t"
"vmov.s32 r2, d9[1] \n\t"
"add %[hitCount], r0 \n\t"
"add %[hitCount], r1 \n\t"
"add %[hitCount], r2 \n\t"
: [a] "+r" (a), [hitCount] "+r" (hitCount)
: [pixelCount] "r" (pixelCount), [image] "r" (image), [checkColor] "r" (checkColor)
: "r0", "r1", "r2", "r3", "r4", "r5", "r6", "q0", "q1", "q2", "q3", "q4", "cc", "memory"
);
totalHitCount += hitCount;
}
int endTime = getTime();
NSString* string = [NSString stringWithFormat:@"Pixcel: %d\nHit Pixel: %d\nTime: %d msec\n", pixelCount * LOOP_COUNT, totalHitCount, endTime-startTime];
return string;
}